Стоимость "пяти девяток"¶
99,999 - это 5 минут 26 секунд простоя в год (или 26 секунд в месяц).
Понятно же, что для такой доступности любые ручные операции в критическом пути должны быть исключены, система должна сама перезапускать упавшие сервисы, перенаправлять трафик, подключать резервные мощности и т.п. без какого-либо участия человека, должны быть полностью дублированы все критические компоненты (N+2, минимум N+1) с устранением единых точек отказа (SPOF, single point of failure), сервис должен работать минимум в двух, а лучше в трёх независимых географических зонах (availability zones) или регионах с автоматическим переключением при сбое (failover), должны быть реализованы Zero-touch deployment (полностью автоматизированные пайплайны CI/CD) и инфраструктура как код (IaC), graceful degradation (при серьезных проблемах система должна сама отключать неключевые функции, сохраняя работоспособность ядра), должны быть предиктивные алерты (система должна предупреждать о потенциальных проблемах (рост latency, исчерпание ресурсов) до того, как они приведут к простою), любые изменения (код, конфигурация, инфраструктура) должны проходить через автоматизированное тестирование и канареечные/поэтапные rollout, и т.д. и т.п....
Часто (особенно у бизнеса) возникает в корне ошибочное предположение, что добавление девяток в аптайм происходит линейно, как с точки зрения прибыли, так и связанных с этим затрат.
К огромному сожалению, это предположение только создаст ненужную и бесполезную нагрузку на инженеров, которым придется разрабатывать и поддерживать такой сервис.
Все понимают, что аптайм никогда не будет 100%, потому что в нашем мире нет систем и сервисов, которые требуют такой надежности.
Чем больше девяток в SLO, тем сложнее и дороже этого достичь.
Например, Google при определении SLO предлагает использовать "happiness test": SLO устанавливается на том уровне, который нечасто случаясь, оставляет типичного пользователя сервиса счастливым.
Для "пяти девяток" использование ручных операций неприемлемо (ручные действия не исключаются полностью, просто они выводятся за пределы критического пути восстановления). Все рутинные операции, обнаружение и восстановление при стандартных сбоях должны быть автоматизированы.
Представьте, сколько это стоит? Даже не говоря о том, как все это сделать организационно и процессно.
Возьмем, для примера, окно в 30 дней:
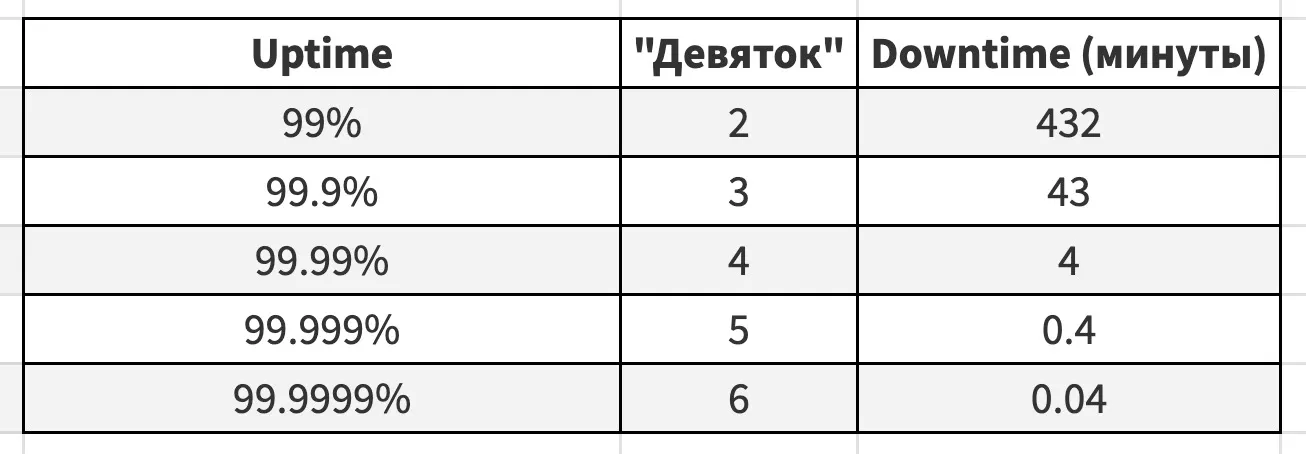
При переходе с 2-х девяток (99) до 3-х девяток (99,9) мы получаем колоссальный прирост времени безотказной работы, примерно 389 минут, это почти плюс 6 с половиной часов безотказной работы в месяц, почти целый рабочий день! Это значительный прирост времени безотказной работы и надежности! Все довольны, инженерам можно немножко начать разгребать бэклог.
Но!! Переход с 4-х девяток (99,99) до 5-ти девяток (99,999) дает нам прирост времени безотказной работы всего на 3 минуты в месяц (сколько такой переход стоит в деньгах посчитайте сами). Это кому-то нужно? Пользователи это вообще заметят?
Слов к делу не пришьешь, сейчас вставим график (не совсем в масштабе, но смысл понятен):
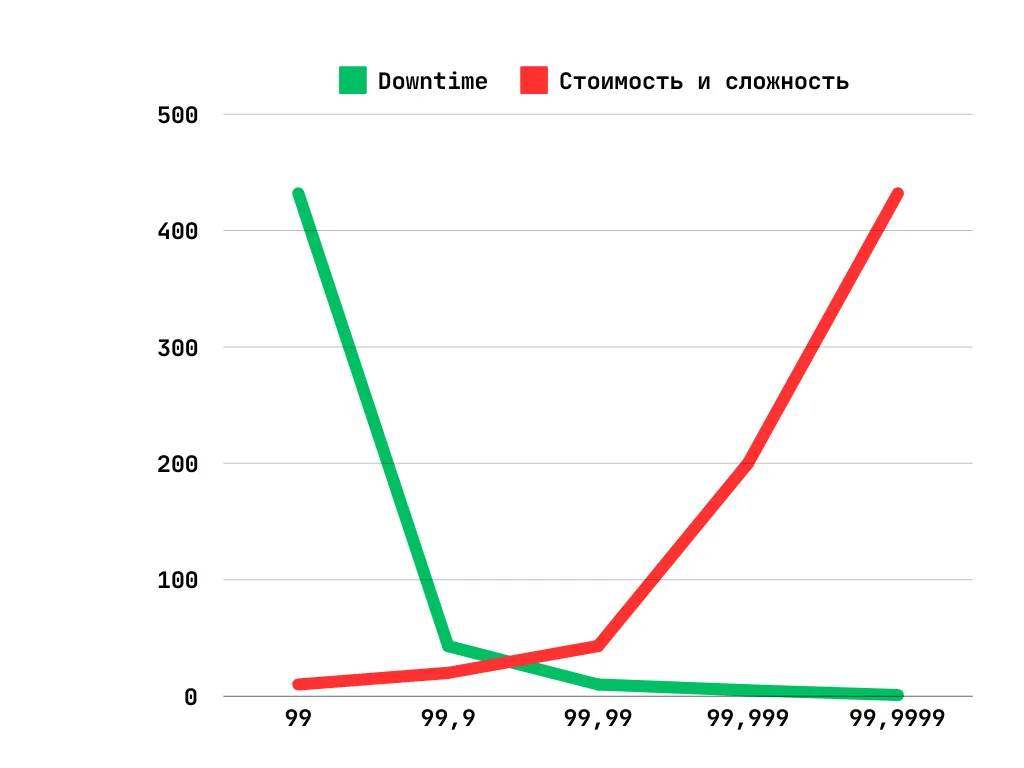
Для бизнеса это немножко не то, что они хотят видеть. Как и увеличение времени безотказной работы, дополнительные затраты и сложность являются совсем не линейными.
Когда вы начинаете добавлять девятки, особенно после трех девяток, это становится чрезвычайно дорогостоящим и сложным процессом.
Каждая дополнительная "девятка" увеличивает надежность системы в 10 раз, но и одновременно увеличивает ее стоимость тоже в 10 раз.
Как уже написано выше, для обеспечения простоя менее 5 минут в месяц требуется высокий уровень резервирования, распределенности и автоматизации. То есть, большинство аварий должны решаться автоматически, без участия человека. Вы не можете продавать "99,99" и надеяться, что когда что-то упадет, то придет дежурный SRE и все починит. Хотя, некоторые могут :)
Стоимость "пяти девяток" (99,999 доступности) в SRE это не фиксированная сумма, а экспоненциальный рост затрат и сложности, где каждая дополнительная девятка требует значительно бóльших инвестиций в инфраструктуру, автоматизацию, мониторинг и команду инженеров, при этом снижение даунтайма становится все меньше (с 5+ дней до 5+ минут в год). Это требует баланса между бизнес-ценностью и дороговизной, ведь на уровне 99,999 пользовательские сбои могут быть незаметны пользователю, но их устранение стоит очень дорого, а ROI падает.
Есть всем (наверное) известная Reliability Map (видео про нее: Introducing the Reliability Map — r9y.dev), которая поможет вам оценить, что у вас уже есть, чего вы хотите достичь, и поможет составить план изменений в инструментах, процессах и культуре.
Все сводится к созданию требований, которые приведут к ситуации, когда ваши пользователи довольны, но не более того. Излишняя надежность обходится дорого.
Что включает в себя "стоимость" 99,999:¶
- Инфраструктура: высокая избыточность, геораспределение, резервирование всех компонентов (сети, серверы, хранилища, базы данных).
- Автоматизация: максимальная автоматизация развертывания, восстановления, тестирования и мониторинга, чтобы минимизировать человеческий фактор.
- Команда SRE: высококвалифицированные инженеры, которые стоят дорого (зарплаты могут быть высокими, ориентируйтесь на рыночные данные в России для SRE-специалистов).
- Обучение сотрудников: чтобы повысить осведомленность о важности надежности, может потребоваться инвестировать в обучение. Обучение должно затрагивать не только рядовых сотрудников. Для реальных изменений необходимо, чтобы руководство, разработчики и продуктологи говорили на одном языке и рассматривали надежность как приоритетную задачу.
- Процессы: строгие SLO/SLA, детальный мониторинг, управление инцидентами, бюджет ошибок (Error Budget).
- Сложность: постоянная борьба с незаметными, но дорогими в устранении проблемами, что требует глубокой экспертизы (смотри пункт 3).
- Рефакторинг: возможно, потребуется переписать код, чтобы погасить технический долг или использовать более надежный алгоритм. Это не происходит в одночасье: планирование, изучение, рефакторинг, миграция требуют времени и сопряжены с реальными затратами на разработку.
- Изменение архитектуры: иногда требуется полностью переработать систему, чтобы она соответствовала новым нефункциональным требованиям, таким как масштабируемость, надежность и безопасность. Помимо прочего, может потребоваться резервное копирование или отработка отказа, добавление отказоустойчивости, добавление резервных систем переключения при сбоях.
- и т.д.
- и т.п.
Высокая надежность стоит дорого. Эти затраты должны соотноситься с бизнес-целями и быть обоснованы прибылью от этого сервиса.
Как утверждает Alex Idalgo в своей книге "Implementing Service Level Objectives: A Practical Guide to SLIs, SLOs, and Error Budgets"":
"Стремление к идеальной надежности не только невозможно, но и невероятно дорого. Ресурсы, необходимые для приближения к 100%, растут по кривой, которая круче линейной. Поскольку достичь 100% невозможно, вы можете потратить бесконечные ресурсы и так и не добиться цели".

На практике главная сложность в том, чтобы убедить высшее руководство, что перфекционизм контрпродуктивен.
Цель SRE найти оптимальный баланс (ROI) между затратами и реальной ценностью для бизнеса. Стремление к "пяти девяткам" оправдано только для критически важных систем (финансы, телекоммуникации), где простой стоит миллионы в минуту, а не для большинства сервисов, где 99,9% уже дает огромную надежность при гораздо меньших затратах.