Теория надежности¶
Теория надежности - это не изобретение IT-инженеров. Это классическая научная дисциплина, которая родилась в аэрокосмической и военной промышленности, где цена отказа измеряется человеческими жизнями. Её задача - предсказать, как долго будет работать самолётный двигатель, электростанция или спутник, и как минимизировать риски их поломки.
Теория надежности это фундамент, на котором построена дисциплина Site Reliability Engineering. SRE не изобретает новые теории, а адаптирует классические методики для динамичного мира распределенных IT-систем.
Теория надежности изучает:
- закономерности отказов: почему и как ломаются системы и причины и модели возникновения отказов;
- методы обеспечения надежности: как спроектировать, создать и использовать систему, чтобы она работала так, как от нее ожидается;
- количественные показатели: как измерить эту самую "работоспособность" в цифрах, а не в "ощущениях".
Проще говоря, теория надежности отвечает на три фундаментальных вопроса о любом объекте:
- Как часто он ломается?
- Как быстро его можно починить?
- Какова вероятность, что он будет работать, когда это нужно?
Теория надежности устанавливает и изучает количественные показатели надёжности и исследует связь между показателями эффективности и надёжности - тот самый компромисс между хотелками продукта и эксплуатации.
Основные понятия и определения теории надёжности сформулированы в ГОСТах серии 27 (ГОСТ 27.XXX "Надежность в технике") - это основополагающая нормативная база по надежности технических систем, разработанная в СССР и действующая в России. Например: ГОСТ 27.002—89 "Надёжность в технике. Основные понятия. Термины и определения" - это лишь один ГОСТ из этой серии, их много и они очень интересные, рекомендую ознакомиться и открыть для себя много нового.
История¶
Теория надежности возникла не в один момент (и, шок-контент, не Google ее придумал), а эволюционировала на протяжении XX века, стимулируемая войнами, космической гонкой и развитием сложных технологий.
1. Истоки (1920 - 1940 годы): статистика и "анализ выживаемости"¶
- Основная мысль: проблема старения и отказов изучалась в рамках статистики и теории вероятностей.
- Ключевые события и люди:
- 1920-30-е: Работа Вальтера Шухарта (Walter Shewhart) по статистическому контролю качества на производстве (Statistical method from the viewpoint of quality control). Заложены основы для анализа вариаций и дефектов.
- 1930-е: Анализ выживаемости (Survival Analysis) в биологии и медицине для изучения продолжительности жизни. Формализованы понятия функции выживания, интенсивности отказов (hazard rate).
- Что производилось: Военная техника, электронные лампы. Проблема: компоненты выходили из строя слишком часто, но системного подхода не было.
2. Рождение как инженерной дисциплины (1940 - 1950 годы): Вторая мировая и холодная война¶
- Основная мысль: сложная военная техника (самолеты, радары, ракеты) была ненадежной. Возникло осознание того, что надежность нужно проектировать, а не просто проверять.
- Ключевые события:
- Вторая мировая война: американские военные столкнулись с чудовищной ненадежностью электронного оборудования. До 70% (sic!) радиоаппаратуры отказывало при транспортировке и использовании.
- 1946: создание AGREE (Advisory Group on Reliability of Electronic Equipment, Консультативной группы по надежности электронного оборудования Министерства обороны США) по заказу Министерства обороны США. Это поворотный момент. Группа впервые сформулировала инженерный подход к надежности.
- 1952: опубликован первый официальный отчет AGREE, ставший фундаментом теории. В нем были определены ключевые понятия: интенсивность отказов, MTTF, необходимость испытаний, важность проектирования для надежности. Сам отчет найти не смог, но нашел Reliability of Military Electronic Equipment ("Надежность военного электронного оборудования") 1957 года. Кстати, в этой книге дается строгое статистическое определение надежности как "вероятности безотказной работы в заданных условиях в течение определенного времени".
- Что производилось: сложные электронные системы, баллистические ракеты, спутники.
В 50-х годах двадцатого века в СССР также были созданы первые группы надежности: в ВВА им. Жуковского и ЦНИИ 22 МО (сейчас это ЦНИИ Воздушно-космических сил РФ). В конце 1950-х в НИИ МЭП была разработана первая отраслевая методика расчета надежности. Тогда же появилось математическое определение термина "надежность":
Надежность (reliability) есть вероятность того, что устройство выполняет свои функции в соответствии с предъявляемыми требованиями в течение заданного интервала времени.
Со временем появилось и другое определение:
Надежность является интегральной функцией распределения вероятности безотказной работы от момента включения до первого отказа.
И наконец короткое определение, давшее начало следующему этапу разработки теории:
"Надежность — это вероятность безотказной работы.
3. Формализация и расцвет (1960 - 1970 годы): космическая гонка и ядерная энергетика¶
- Основная мысль: надежность становится критически важной для репутации и безопасности. Появляются математические модели и стандарты.
- Ключевые события:
- Аполлон-13 (1970): ярчайший пример прикладной надежности и важности процедур восстановления (MTTR). Инженеры на земле создали "фильтр" (легендарный "LiOH canister") из подручных средств - триумф инженерной мысли, загуглите, почитайте, восхититесь настоящими инженерами!
- 1960-е: активное развитие теории надежности систем (System Reliability). Появление моделей для последовательных, параллельных и сложных соединений.
- Рост индустрии: создаются первые профессиональные общества (IEEE Reliability Society), журналы, университетские курсы. Надежность становится обязательной частью инженерных контрактов, особенно в аэрокосмической и оборонной отраслях.
- 1975: Классический учебник "Reliability Engineering" by L. S. Srinath.
- Что производилось: космические корабли, ядерные реакторы, коммерческая авиация.
На этом этапе были разработаны новые требования к надежности, заложившие основу современных систем и программ обеспечения надежности. В начале 1960-х при Госстандарте СССР создан научно-технический совет по проблемам надежности. В середине 1960-х на предприятиях оборонного комплекса были созданы службы надежности. В 1969 году начал выходить журнал "Надежность и контроль качества". В середине 1970-х в журнале "Известия АН СССР" - "Техническая кибернетика" открыт раздел "Теория надежности". В 1985 был издан справочник "Надежность технических систем" под редакцией И. А. Ушакова с участием большого числа авторов не только из СССР, но и из США и других стран, обобщивший мировой опыт теоретических разработок и практических исследований надежности.
4. Компьютерная эра и переход к софту (1980 - 2000 годы)¶
- Основная мысль: отказы стали часто происходить не из-за аппаратного износа, а из-за ошибок в программном обеспечении и сложных взаимодействий.
- Ключевые события:
- Появление стандартов: MIL-STD-785, IEC 61508 (функциональная безопасность).
- Исследования надежности программного обеспечения (Software Reliability), модель Джелински-Моранды (Z.Jelinski, Р.Moranda) - она же "Модель роста надежности", модель Муса (об оценке надежности ПО на этапе эксплуатации по результатам тестирования).
- Развитие концепций отказоустойчивости (Fault Tolerance) и высокодоступных систем (High Availability).
- Что производилось: телекоммуникационные сети, банковские системы, первые датацентры.
5. Эра SRE и облаков (2000-е — настоящее время)¶
- Основная мысль: в условиях распределенных облачных систем, состоящих из тысяч сервисов, классические аппаратные модели не работают. Отказы становятся нормой, а целью становится осмысленное управление этими отказами.
- Ключевые события:
- 2003: статья Google "The Google File System", заложившая культуру проектирования с учетом отказов.
- Середина 2000-х: формирование Site Reliability Engineering (SRE) в Google под руководством Бена Трейнора. Переосмысление теории надежности для мира софта.
- 2010-е: популяризация SRE: книги Google, распространение Chaos Engineering (Netflix, 2010), культуры постмортемов (blameless), управления через SLO/Error Budgets.
Итоговая хронология:¶
Теория надежности оформилась как самостоятельная инженерная дисциплина в середине 1950-х годов (после отчета AGREE), выросла из статистики и анализа выживаемости 1920-30-х. Её расцвет пришелся на 1960-70-е с развитием аэрокосмической отрасли. В 1980-90-е она адаптировалась к миру программного обеспечения, а в XXI веке была радикально переосмыслена и популяризирована практикой SRE, став основой для управления современными облачными системами, где отказы это не аномалия, а данность, которой нужно грамотно управлять.
Теория надежности возникла не в один момент, а эволюционировала на протяжении XX века, стимулируемая войнами, космической гонкой и развитием сложных технологий.
Теория надежности возникла как ответвление от статистики и теории вероятности ещё в XIX веке и первоначально использовалась морскими страховыми компаниями и компаниями по страхованию жизни для оценки, какие тарифы будут прибыльными в реалиях тех времён. В 30-40-х годах XX века были заложены принципы расчёта надёжности энергосистем. С тех пор наука об отказах техники развивается параллельно с самой техникой.
Классические модели надёжности ПО (Джелински-Моранды, Муса) заложили важный фундамент, но в современной практике SRE используются более комплексные подходы. Вместо попыток предсказать момент отказа, мы определяем допустимый уровень ошибок через SLO, строим системы с расчётом на неизбежные сбои и управляем надёжностью как экономическим компромиссом между стоимостью простоя и инвестициями в стабильность.
Классические модели предполагают, что:
- ошибки независимы и равномерно распределены
- исправление ошибок идеально (не вносит новых)
- система статична (не меняется во время эксплуатации)
- не учитывают человеческий фактор и процессы
- не учитывают качество тестирования
- игнорируют влияние DevOps-практик
- не работают с микросервисной архитектурой
- и т.д. и т.п.
Современные подходы - это:
- SLO/Error Budget-ориентированное управление, когда вместо предсказания "когда сломается", мы определяем допустимый уровень ошибок и управляем им,
- метрики на основе перцентилей (percentile-based metrics), когда вместо средних значений используем перцентили, чтобы понимать реальный пользовательский опыт,
- модель "Время до нарушения SLO" (Time-to-SLO-Violation), когда мы прогнозируем не "когда система упадёт", а "когда мы нарушим SLO",
- модель "Надёжности как экономического компромисса", это, наверное, самый важный современный подход: надёжность — это не техническая характеристика, а экономическое решение,
- модель "Распространения ошибок" (Failure Propagation), когда мы анализируем, как отказ одного компонента влияет на всю систему,
- модель "Зависимостей" (Dependency Mapping), когда мы строим граф зависимостей сервисов (Reliability Block Diagrams) и вычисляем "что от чего зависит и что пострадает, если что-то упадет",
- модель MAD (Median Absolute Deviation) для обнаружения аномалий без предварительного обучения, когда вместо классического
если > X, то алертмы используемесли значение отклоняется от медианы больше чем на N*MAD, - модель прогнозирования на основе сезонности (Facebook Prophet, Holt-Winters), когда мы учитываем суточные циклы, дни недели, праздники, времена года и т.п.,
- chaos engineering, когда мы не предсказываем, а проверяем поведение системы при отказах,
- ML-подходы,
- и т.д. и т.п.
Теория надежности: суть (очень-очень кратко)¶
Теория надежности - это инженерная дисциплина, изучающая способность системы выполнять требуемые функции в заданных условиях в течение заданного периода времени.
Ключевые понятия:
- Надежность (Reliability): вероятность того, что система будет работать безотказно в течение определенного времени. Измеряется как
R(t) = e^(-λt), гдеλ— интенсивность отказов. Ради точности уточню, что эта формула справедлива только для периода нормальной эксплуатации (экспоненциальное распределение), в фазах приработки и износа (смотри ниже про "ванну") распределения другие (Вейбулла и другие). - Интенсивность отказов (Failure Rate, λ): количество отказов в единицу времени. Для сложных систем часто следует "ваннообразной кривой":
- Период приработки (Early "Infant Mortality" Failures): высокий уровень отказов из-за дефектов производства.
- Период нормальной эксплуатации (Constant Failure Rate): отказы носят случайный характер, интенсивность постоянна.
- Период износа (Wear-Out Failures): отказы из-за старения и износа компонентов.
- Среднее время наработки на отказ (Mean Time To Failure, MTTF): среднее время работы системы до отказа.
MTTF = 1 / λ(для периода нормальной эксплуатации). - Среднее время восстановления (Mean Time To Restoration, MTTR): среднее время, необходимое для восстановления работоспособности системы после отказа.
- Доступность (Availability): доля времени, когда система работоспособна. Рассчитывается как:
Availability = MTTF / (MTTF + MTTR)- или
Availability = Uptime / (Uptime + Downtime) - часто выражается в "девятках" (например, 99,9% — "три девятки")
- в реальных системах используется
A = (MTBF - MTTR) / MTBF, гдеMTBF = MTTF + MTTR.
- Стабильность: WTF? "Cтабильность" это неформальный бытовой термин, который может означать либо надёжность, либо доступность, либо предсказуемость поведения.
Методики оценки отказов в контексте SRE¶
Количественные метрики (SLI, SLO, SLA)¶
Это прямой перевод теории надежности на язык бизнес-целей и пользовательского опыта.
Полее подробно про SLO и SLI в главах SLI: Что измеряем?, SLO: Какой уровень надежности хотим? и Как определить свои SLI и SLO?
SLO — это практическая реализация целевого показателя надежности. Если SLO по доступности установлен на 99,95%, это означает, что мы проектируем систему с определенными MTTF и MTTR, чтобы достичь этой цели.
Анализ и моделирование отказов¶
SRE использует методики, чтобы не просто реагировать на отказы, а предвидеть и предотвращать их.
-
Постмортемы (Blameless Postmortem)
- Суть: глубокий анализ каждого значительного инцидента. Это аналог "анализа причин отказа" в инженерии.
- Цель: не найти виноватого, а понять коренную причину (Root Cause) и выработать действия по улучшению системы и процессов, чтобы предотвратить повторение.
- Связь с теорией: позволяет "сдвинуть" систему из фазы "приработки" (где много багов) в фазу "нормальной эксплуатации" путем устранения системных недостатков.
-
Упражнения по контролируемому хаосу (Chaos Engineering)
- Суть: это проактивная методика оценки отказов. Вместо того чтобы ждать, когда система откажет сама, мы намеренно вводим сбои в контролируемой среде.
- Примеры: "убить" случайный сервер, добавить задержку в сеть, исчерпать память.
- Цель: проверить гипотезы о том, как система ведет себя при отказах, выявить скрытые зависимости и слабые места до того, как они вызовут реальный инцидент.
- Связь с теорией: это форма испытаний на надежность, но проводимых в продакшене (или его точной копии). Помогает оценить реальную интенсивность отказов и эффективность механизмов восстановления.
-
Управление рисками через "Error Budget"
- Суть: это, пожалуй, ключевое концептуальное нововведение SRE. "Бюджет ошибок" вычисляется из SLO.
Error Budget = 1 - SLO- Пример: при SLO доступности 99,9% бюджет ошибок составляет 0.1%. Это означает, что сервис может быть недоступен около 43 минут в месяц.
- Как используется: бюджет ошибок — это не "лимит отказов", а ресурс для скорости и инноваций. Пока бюджет не исчерпан, команда разработки может спокойно выпускать новые функции (которые потенциально могут вызвать сбои). Если бюджет исчерпан, все силы бросаются на повышение надежности, а выпуск новых функций приостанавливается.
- Связь с теорией: это механизм, который формализует компромисс между надежностью (Reliability) и скоростью разработки (Velocity), переводя его в объективные, измеримые термины.
- Суть: это, пожалуй, ключевое концептуальное нововведение SRE. "Бюджет ошибок" вычисляется из SLO.
SRE как прикладная теория надежности¶
| Классическая теория надежности | Практика SRE |
|---|---|
| Интенсивность отказов (λ) | Service Level Indicators (SLI), например, процент ошибок. |
| Вероятность безотказной работы (R(t)) | Service Level Objective (SLO). |
| Среднее время наработки на отказ (MTTF) | Измеряется через SLI (например, время между инцидентами). |
| Среднее время восстановления (MTTR) | Ключевой метрика для SRE-команды. Цель — минимизировать. |
| Анализ причин отказа | Процедура проведения постмортемов. |
| Резервирование и избыточность | Использование избыточных компонентов, зон доступности, регионов. |
| Испытания на надежность | Упражнения по контролируемому хаосу (Chaos Engineering). |
| Проектирование для надежности | Создание отказоустойчивых архитектур, идемпотентных API, механизмов ретраев (повторных попыток) и т.д. |
Основные мысли и концепции теории надежности:¶
1. Отказ - это событие, а не состояние. Это самая важная мысль. Надежность - это вероятностная мера. Система не бывает "надежной" или "ненадежной" в абсолютном смысле. Мы говорим: "Вероятность того, что система проработает безотказано в течение следующих 1000 часов, составляет 0,95 (или 95%)". Это смещает фокус с поиска "идеала" на управление рисками. То есть, мы понимаем, что нет на 100% надежных систем.
2. Надежность и отказ определяются через функцию. Система считается отказавшей не когда она "сломана", а когда перестает выполнять требуемую функцию в заданных условиях. Один и тот же физический дефект может быть отказом в одних условиях (например, сбой GPU для геймера) и не быть им в других (для сервера, у которого этих GPU десятки).
3. Сложные системы отказывают сложным образом. В сложных системах (а современные IT-системы это эталон сложности) отказы редко имеют одну причину. Чаще всего это цепочка событий и сочетание скрытых дефектов, которые выстраиваются в "идеальный шторм". Это приводит к мысли о необходимости анализа не отдельных компонентов, а их взаимодействий и зависимостей.
4. "Ванна" и её три фазы жизни системы.
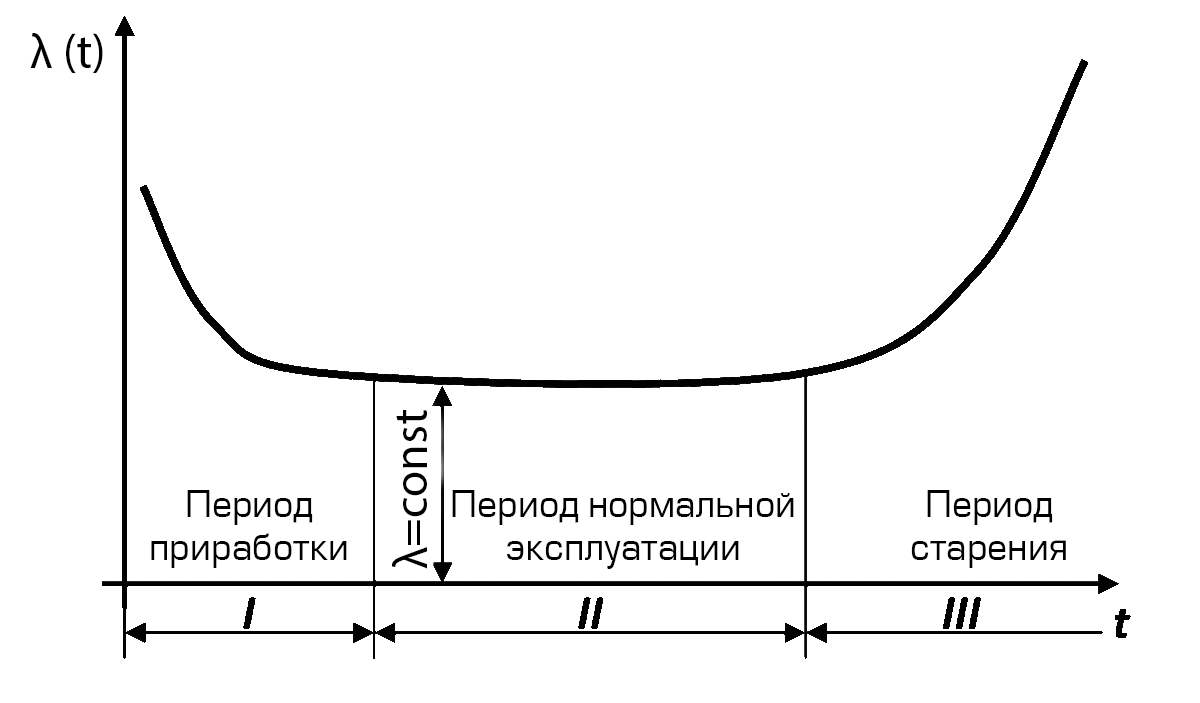
Кривая интенсивности отказов в виде ванны это мощная модель для понимания "жизни" системы:
- Период приработки (ранние отказы): отказы из-за латентных дефектов и ошибок производства/разработки. Мысль: чтобы повысить надежность, нужно "пропустить" систему через эту фазу на стенде (тестирование, "прогрев").
- Период нормальной эксплуатации (случайные отказы): отказы редки, случайны и непредсказуемы. Интенсивность отказов примерно постоянна. Мысль: в этой фазе бороться за надежность - значит бороться с внешними воздействиями и создавать резервы.
- Период износа (отказы из-за старения): отказы учащаются из-за износа, старения, накопления повреждений. Мысль: требуется плановое техническое обслуживание, замена компонентов до наступления этого периода.
5. Надежность и доступность — не одно и то же.
Критически важное различие:
- Надежность (Reliability, R(t)): "Как долго система работает непрерывно?" (MTTF — среднее время до отказа). Мера стабильности.
- Доступность (Availability, A(t)): "Как часто система доступна для использования?" (доля времени, когда система работоспособна). Мера готовности. Система может быть высокодоступной (A=99,99%), но ненадежной (часто падает и быстро поднимается, т.е. низкий MTTF, но очень низкий MTTR).
Моя любимая аллегория: ваша любимая кофейня открыта, вы можете туда зайти, но купить свой любимый лавандово-ванильный раф не можете, потому что внутри нет электричества и бариста пьяный в хлам лежит в подсобке.
6. Резервирование - ключевой метод повышения надежности. Мысль: отказы отдельных компонентов неизбежны, но систему можно сделать надежной, вводя избыточность.
- Активное резервирование: все компоненты работают параллельно. Система откажет, только если откажут все.
- Пассивное ("холодное") резервирование: резервный компонент включается только при отказе основного. Требует времени на переключение.
- Мысль: резервирование увеличивает сложность, что само по себе может стать новым источником отказов (например, ошибки в механизме переключения).
7. Восстановимость — такой же важный параметр, как и безотказность. Теория говорит: полная безотказность недостижима или экономически нецелесообразна или, проще говоря, "стопроцентно надежные системы строить дорого и нецелесообразно". Поэтому ключевой мыслью становится проектирование не только для предотвращения отказов, но и для минимизации времени восстановления (MTTR). Мы понимаем, что отказы однозначно будут и умеем их быстро обнаруживать, локализовывать, быстро и дешево исправлять и возвращать сервис в работу, это намного важнее, чем пытаться избежать отказа любой ценой.
8. Стоимость надежности растет экспоненциально. Каждая следующая "девятка" доступности (с 99% до 99,9%, затем до 99,99%) обходится на порядок дороже. Это приводит к фундаментальной мысли о компромиссе. Надежность не абсолютное благо, а один из параметров, который нужно балансировать со стоимостью, временем выхода на рынок и функциональностью.
9. Человеческий фактор - ключевое звено. High Reliability Organization пришла к выводу, что в самых надежных системах (авиация, АЭС) критическую роль играет организационная культура: поощрение сообщений об ошибках, отсутствие поиска виноватых (blameless culture), обучение на инцидентах, распределенная ответственность.
Короче говоря:¶
Основная мысль теории надежности:
Надежность - это вероятностная характеристика, которую можно и нужно измерять, проектировать и управлять ею через осознанный компромисс между безотказностью, восстанавливаемостью, сложностью и стоимостью, с пониманием, что отказы — неизбежная часть жизненного цикла любой сложной системы.
Именно эти принципы SRE переводит в практические методики: SLO формализует компромисс, постмортемы реализуют культуру обучения, Error Budget управляет стоимостью надежности, а Chaos Engineering проверяет, как система ведет себя в фазе "случайных отказов".
Методики SRE - это инструменты для управления надежностью как динамическим, а не статическим свойством сложной, постоянно меняющейся системы.
И это не "какое-то непонятное что-то за много денег".