Про RTO и RPO¶
Все системы в компании работают не просто так, а для различных нужд/целей. В случае аварии компания теряет деньги. Показатели RTO и RPO – то, что говорит о приемлемых размерах этих потерь.
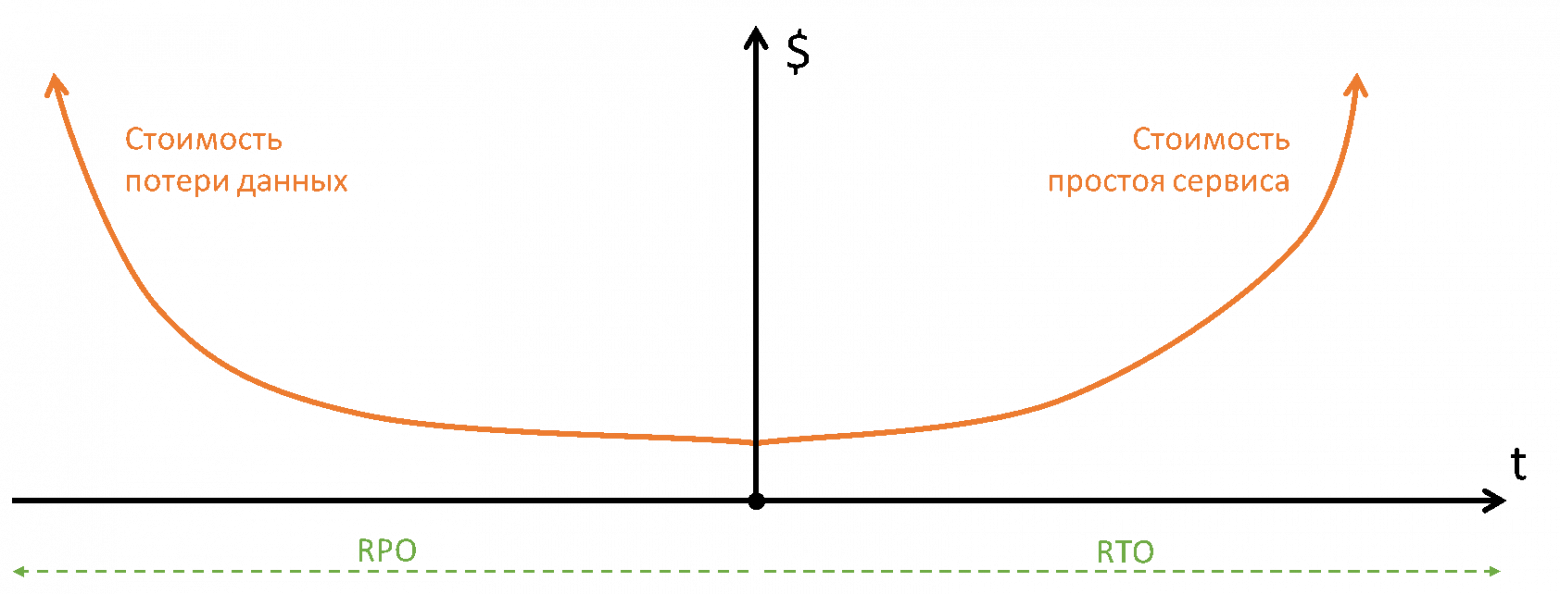
RTO¶
Recovery Time Objective, "целевое время восстановления"
Это промежуток времени, в течение которого система может оставаться недоступной в случае аварии, т.е. время, необходимое для восстановления полного функционирования сервиса после наступления аварийного события.
Например, RTO = 2 часа, если в датацентре произошла авария, и сервис должен быть снова доступен через 120 минут или раньше.
SRE организуют систему так, чтобы за это время восстановить работоспособность системы на резервном оборудовании или площадке с помощью различных технологий отказоустойчивости или восстановления из резервных копий на другой сервер.
RPO¶
Recovery Point Objective, "целевая точка восстановления"
Это максимальный период времени, за который могут быть потеряны данные в результате инцидента.
Например, если для системы определен RPO = 15 минут, это значит, что, в случае аварии систему удастся восстановить, но в ней будут потеряны данные не более, чем за последние 15 минут.
В идеале этот показатель должен стремиться к нулю, однако на практике это нереализуемо.
Вычисление RPO и поддержание ее на нужном уровне относятся к задачам SRE.
RTO, как и RPO, должен быть как можно меньше.
Чем меньшее время простоя сервиса обеспечивает решение по защите, тем дороже такая защита стоит.
Методы, решения и инструменты для обеспечения необходимого RTO и RPO нужно подбирать, находя баланс между возможностями и стоимостью.
ВАЖНО¶
RTO - это НЕ скорость восстановления!
RPO - это НЕ количество потерянных данных! RPO — это не объём (гигабайты) потерянных данных, а максимальный допустимый период времени, за который эти данные могли быть созданы или изменены. Если RPO = 1 час, то резервное копирование должно завершаться успешно и занимать менее часа, а интервал между копиями должен быть меньше часа.
RTO и RPO – это целевые значения , это максимальные рамки, в которые мы должны уложиться.
Их определение всегда должно идти от бизнеса, это задача владельцев бизнеса (Business Owners) или владельцев продукта (Product Owners) при участии технических экспертов (SRE, архитекторов). Техническая команда затем предлагает решения и оценивает их стоимость для достижения заданных целей.
Например:
- задача для RTO:
Для сервиса, в случае сбоя обслуживающей этот сервис системы, необходимо обеспечить восстановление, не допустив простоя в работе этого сервиса более 5 минут (RTO = 5 минут). Значит, подойдет решение, которое позволит сделать систему доступной за срок менее 5 минут.
- задача для RPO:
Для базы данных, в случае ее сбоя, нужно обеспечить восстановление с допустимой потерей данных сроком не более 24 часов от момента сбоя. Значит, подойдет решение, которое обеспечит гарантированное восстановление базы из точек восстановления, производимых чаще, чем 1 раз в сутки. Резервное копирование раз в час, создающее 24 точки восстановления, дает больше гарантий восстановления, чем копирование раз в сутки, делающее только 1 точку.
RPO определяется не частотой бэкапа, а максимально допустимым объёмом потерь. Если вы делаете бэкап каждый час, но на его создание и передачу уходит 20 минут, а данные теряются с момента последнего успешно завершенного бэкапа, то ваш фактический RPO может быть 80 минут (60 + 20), а не 60.
RTO — это про доступность (uptime), а RPO — про целостность данных (data loss).
Классический пример: резервное копирование (backup) и восстановление (restore) хорошо решает задачу RPO (данные есть), но плохо — задачу RTO (восстановление из бекапа может занять часы). А "холодный" резервный стенд (standby) может решать RTO (запустили за 30 минут), но не RPO (данные на момент аварии могут быть утеряны).
Что нужно учитывать¶
- Время на обнаружение аварии.
- Время на понимание последствий аварии: всё сломалось или что-то доступно.
- Время на поиск причины возникновения аварии, или хотя бы локализовать проблему: если пожар – потушить его, прежде чем пытаться восстановить что-либо в ту же инфраструктуру.
- Время на определение способов восстановления (наиболее подходящую процедуру восстановления).
- Время на принятие решения по восстановлению и запуск восстановления.
- Документация Runbooks. Чёткие, актуальные и доступные инструкции резко сокращают время на пункты 4 и 5.
- Автоматизация. Ручное восстановление почти всегда гарантирует превышение RTO для критичных систем.
- Тестирование процедур восстановления (Disaster Recovery Test). Без регулярных учений RTO на бумаге и в реальности могут различаться на порядок.
Все это влияет на общее время восстановления.
MTD (Maximum Tolerable Downtime / Максимально Допустимый Простой)¶
это общий временной лимит, после которого простой наносит бизнесу непоправимый ущерб (потеря клиентов, репутации, штрафы). RTO всегда должен быть меньше MTD, чтобы осталось время на само восстановление, даже если оно займёт всё целевое время.
Взаимосвязь RTO, RPO и стоимость решений¶
Достижение низких значений RTO и RPO требует сложных и дорогих технологий (репликация в реальном времени, географически распределенные кластеры). Выбор стратегии — это всегда компромисс между:
- Допустимыми потерями бизнеса (при долгом простое и потере данных).
- Стоимостью реализации и поддержки решения.
Простая иллюстрация:
- RTO=5 мин, RPO=0: Требуются решения типа актив-актив между ЦОДами с синхронной репликацией данных. Очень дорого.
- RTO=4 часа, RPO=15 мин: Возможно использование "теплого" стенда с асинхронной репликацией или частыми снапшотами. Умеренная стоимость.
- RTO=24 часа, RPO=24 часа: Достаточно налаженного процедурного резервного копирования и виртуализации. Относительно дёшево.
Как перейти от теории к практике?¶
- Классифицируйте: Разделите все сервисы по критичности (Tier).
- Согласуйте: Для каждого Tier получите от бизнеса MTD, а затем определите RTO и RPO.
- Спроектируйте: Выберите архитектурные решения (репликация, бэкапы, геораспределение), которые гарантированно укладываются в целевые показатели.
- Автоматизируйте и документируйте: Создайте автоматические сценарии (playbooks) восстановления.
- Тестируйте: Регулярно проводите плановые учения по восстановлению (Disaster Recovery Drills), чтобы проверять и улучшать реальные показатели.